How does it work? Kubernetes! Episode 1 - Kubernetes general architecture
- 7 minsHey everybody
I hacked something together in order to create a Kubernetes cluster on CoreOS (or Container Linux) using Vagrant and Ansible.
If you keep reading, I’m going to talk to you about Kubernetes, etcd, CoreOS, flannel, Calico, Infrastructure as Code and Ansible testing strategies. It’s gonna be super fun.
The whole subject was way too long for a single article. Therefore, I’ve divided it into 5 parts. This is episode 1, regarding the Kubernetes general architecture.
If you want to try it:
git clone https://github.com/sebiwi/kubernetes-coreos
cd kubernetes-coreos
make up
This will spin up 4 VMs: an etcd node, a Kubernetes Master node, and two Kubernetes Worker nodes. You can modify the size of the cluster by hacking on the Vagrantfile and the Ansible inventory.
You will need Ansible 2.2, Vagrant, Virtualbox and kubectl. You will also need molecule and docker-py, if you want to run the tests.
Why?
The last time I worked with Kubernetes was last year. Things have changed since then. A guy I know once said that in order to understand how something complex works, you need to build it up from scratch. I guess that’s one of the main points of this project, really. Scientia potentia est. I also wanted to be able to test different Kubernetes features in a set up reminiscent of a production cluster. Minikube is great and all, but you don’t actually get to see communication between different containers on different hosts, node failover scenarios, scheduling policies, or hardcore scale up procedures (with many nodes).
Finally, I thought it would be nice to explain how every Kubernetes component fits together, so everyone can understand what’s under the hood. I keep getting questions like “what is a Kubernetes” at work, and if it is “better than a Docker”. You won’t find the answer to the last question in this article, but at least you will (hopefully) understand how Kubernetes works. You can make up your own mind afterwards.
Okay, I was just passing by, but what is Kubernetes?
Kubernetes is a container cluster management tool. I will take a (not so) wild guess and assume that you’ve already heard about Docker and containers in general.
The thing is that Docker by itself will probably not suffice when using containers in production. What if your application is composed of multiple containers? You will need to be able to handle not only the creation of these containers, but also the communication between them. What if you feel that putting all your containers on the same host sucks, since if that host goes down, all your containers die with it? You will need to be able to deploy containers on many hosts, and also handle the communication between them, which translates into port mapping hell unless you’re using an SDN solution. What about deploying a new version of your application without service interruption? What about container failure management, are you going to do go check on every container independently to see if it is healthy, and relaunch it manually if it is not? Grrrrrrrraaaaah.
Kubernetes is a tool you can use if you do not want to develop something specific in order to handle all the aforementioned issues. It can help you pilot your container cluster, hence its name, which means pilot or helmsman in greek.
Just a little heads up before we start talking about architecture: I will often talk about pods during these series. A pod is a group of one or more containers, that run in a shared context. A pod models an application-specific “logical host”, and theoretically it contains one or more applications that are tightly coupled: the kind of applications that you would have executed on the same physical or virtual host before containers. In practice, and for our use-case, you can just think of a pod as a container, since we will only have one container inside each pod.
A standard Kubernetes installation consists of both Master and Worker nodes:
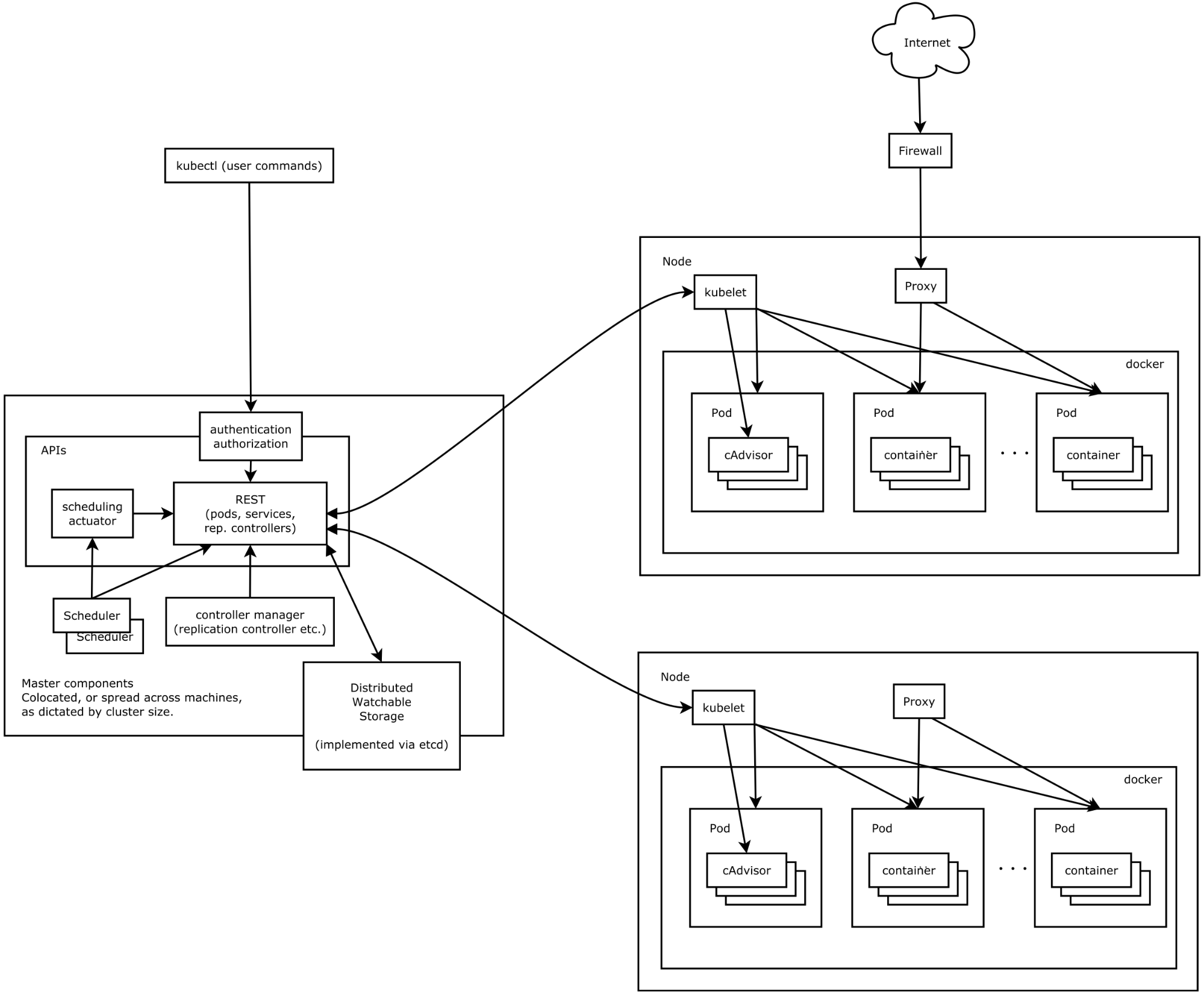
Wait, where is the Master node?
This architecture diagram specifies a set of master components, but not a Master node per-se. You will probably notice that the Distributed Watchable Storage is considered among these components. Nevertheless, we will not install it on the same node. Our Distributed Watchable Storage will be a separate component (more on this later).
So the Master node actually becomes everything that is inside the red square:
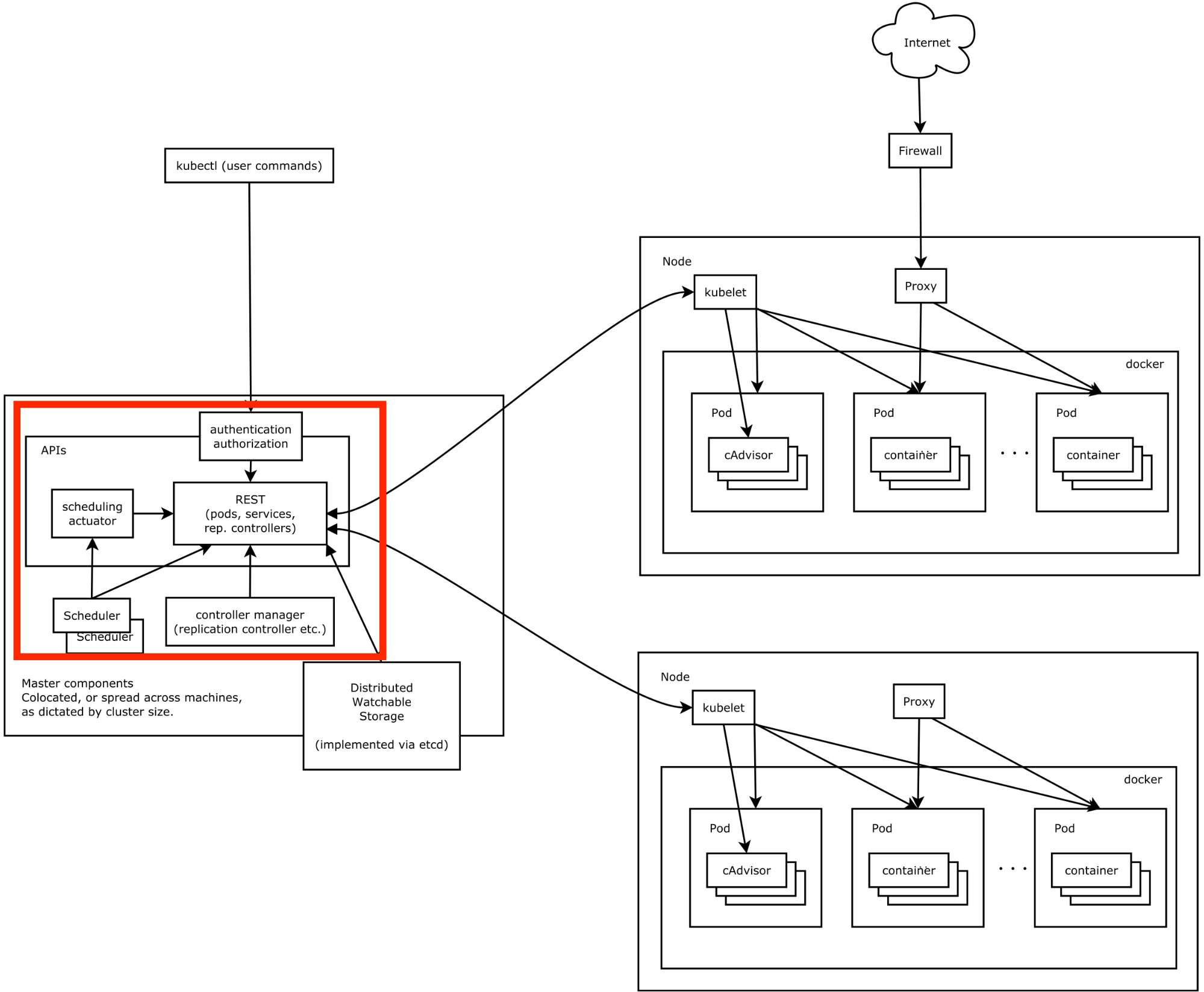
All these components are part of the Kubernetes control pane. Keep in mind that you can have these on one single node, but you can also put them on many different ones. In our case we’re putting them all together. So basically, we have an API server, a Scheduler, and a Controller Manager Server.
The API server exposes the Kubernetes API (duh). It processes REST operations, and then updates etcd consequently. The scheduler binds the unscheduled pods to a suitable worker node. If none are available, the pod remains unscheduled until a fitting node is found. The controller manager server does all the other cluster-level functions, such as endpoint creation, node discovery, and replication control. Many controllers are embedded into this controller manager, such as the endpoint controller, the node controller and the replication controller. It watches the shared state of the Kubernetes cluster using the API server, and makes changes on it with the intention of making the current state and the desired state of the cluster match.
What about the Worker node?
The Master node does not run any containers, it just handles and manages the cluster. The nodes that actually run the containers are the Worker nodes.
Note: This is not actually true in our case, but we will talk about that later, during episode 5.
The Worker node is composed of a kubelet, and a proxy (kube-proxy). You can see these components inside the red square, in the diagram below.
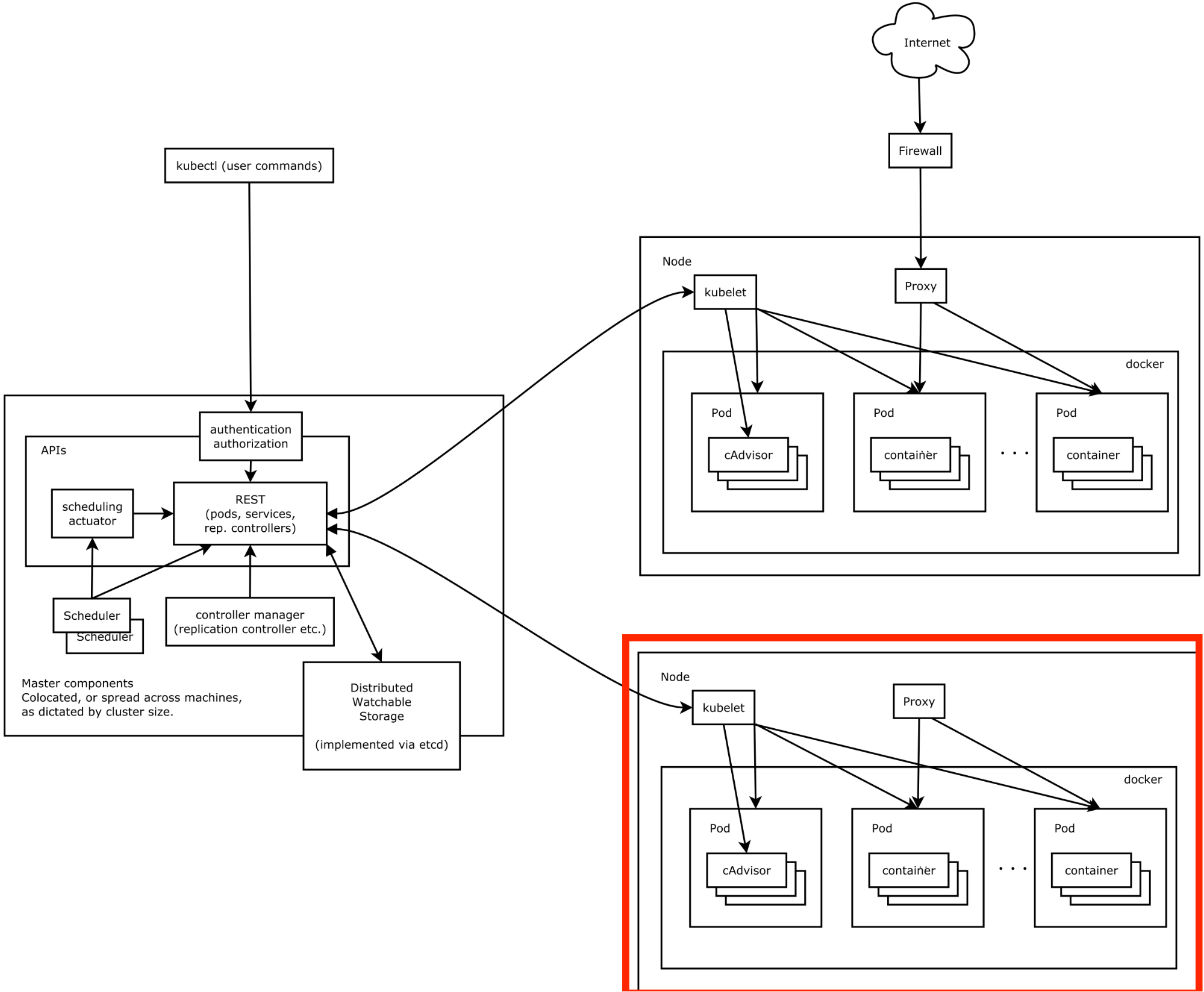
The kubelet is the agent on the worker node that actually starts and stops the pods, and communicates with the Docker engine at a host level. This means it also manages the containers, the images and the associated volumes. It communicates with the API server on the Master node.
The kube-proxy redirects traffic directed to specific services and pods to their destination. It communicates with the API server too.
And what about that Distributed Watchable Storage thing?
Oh, you mean etcd. This is one of the components that is actually included in Container Linux, and developed by CoreOS. It is a distributed, fault tolerant key-value store used for shared configuration and service discovery. It actually means “something like etc, distributed on many hosts”. This sucks is a weird name because it is not a filesystem, but a key-value store. They are aware of it though. Just in case you missed it in the previous diagrams, it is the black square inside the red square:
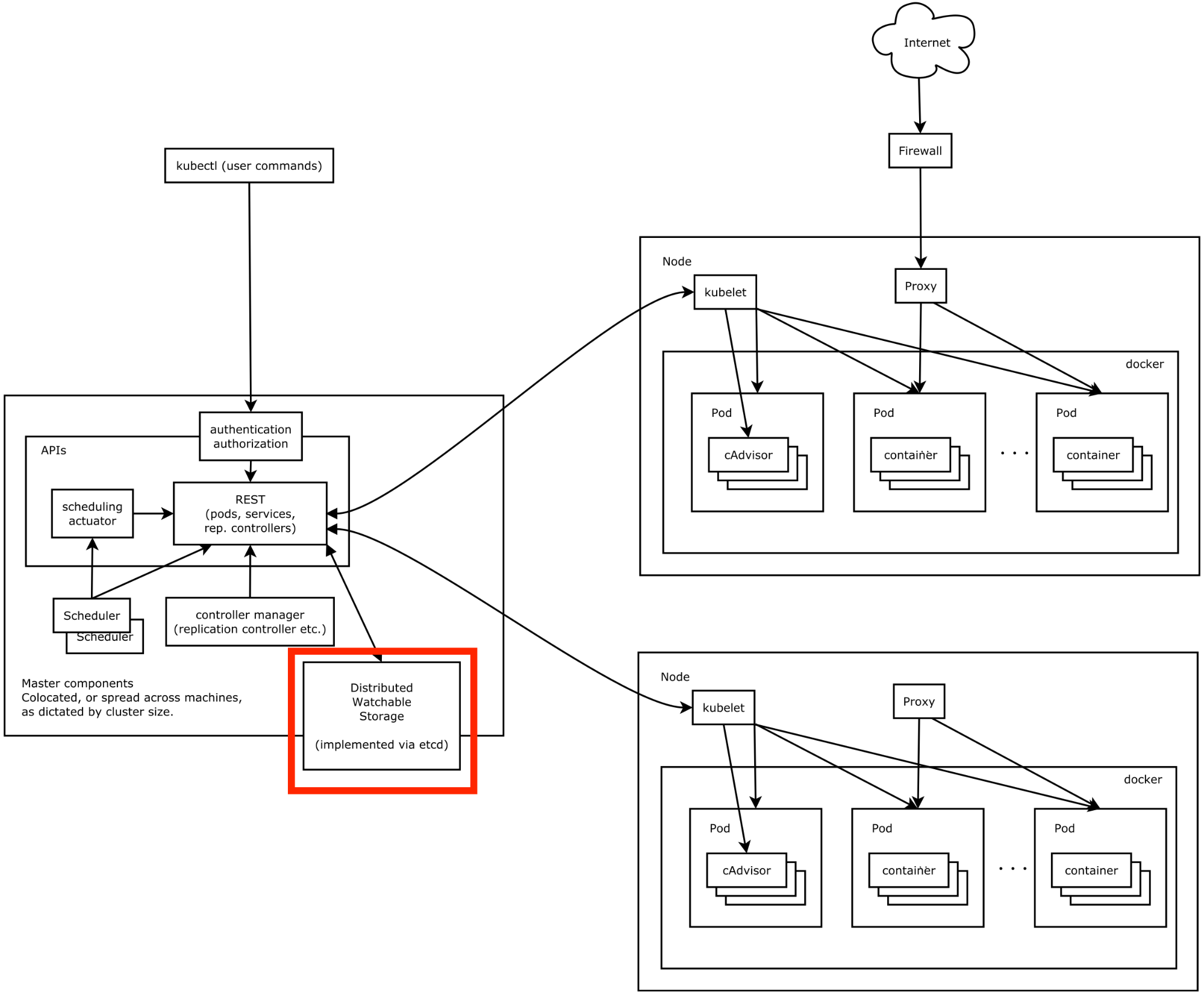
All the persistent master state is stocked in etcd. Since components can actually “watch” components, they are able to realise that something has changed rather quickly, and then do something about it.
And that’s what I deployed on CoreOS using Ansible. All of these things, and then some more.
That’s rad, how did you do it?
You need to understand a little bit about Kubernetes networking before we get to that. That’s all for today though. I’ll talk to you about networking in the next episode.
Stay tuned!

Sebiwi
Perfectionist